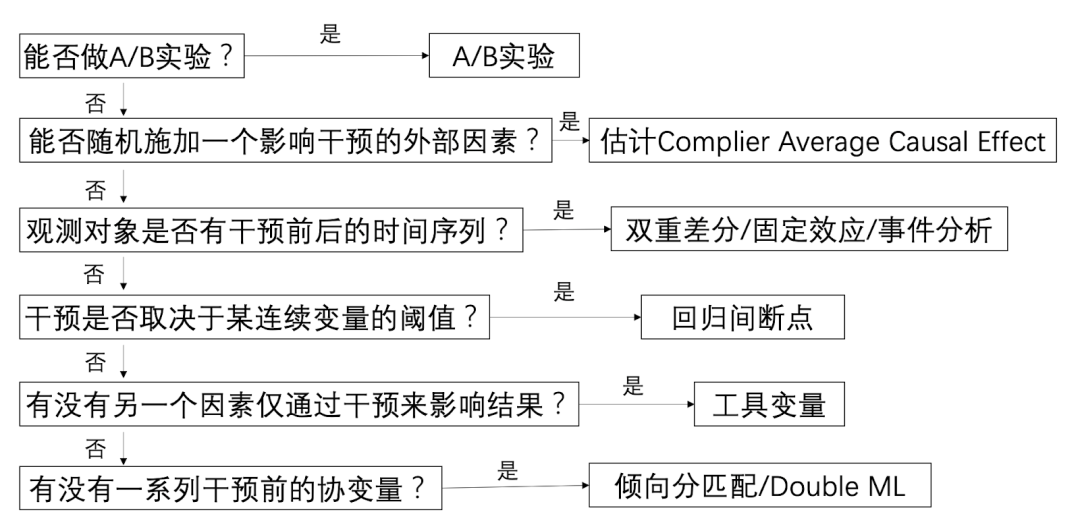
建模方法汇总
因为相关性不等于因果性,所以我们需要通过控制变量去找到因果关系,而因果推断就是一个尝试“找到两个完全一样的��样本,然后通过控制变量去找到因果关系”的过程。
下面介绍三种核心的因果推断方法:统计实验(Statistical Experiment)、准实验(Quasi-experiment)、反事实(Counterfactuals)
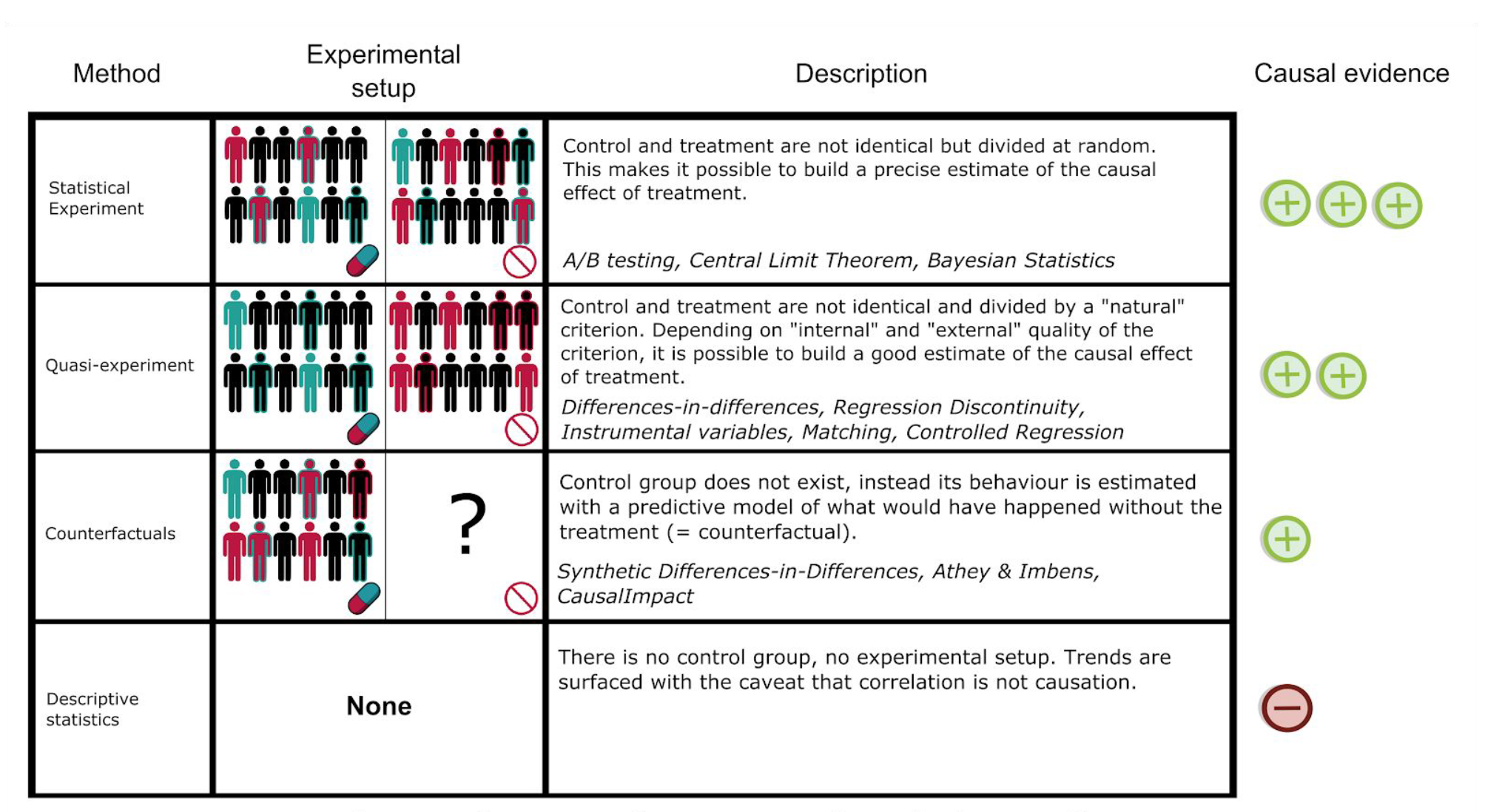
统计实验(Statistical Experiment)
也就是直接设计 AB TEST ,简单粗暴
这种情况下,我们可以通过随机分组来产生实验组和控制组,从而实现“完美”的控制变量。一般使用统计学的假设检验就好,而假设检验也是因果推断中准确度最高的方法。
假设检验很简单,在这里就不详细讲了。
准实验(Quasi-experiment)
这种情况下,实验组和控制组的产生不随机,存在某个因素影响不同组的分流,因此实验组和控制组是“没有完全的控制变量”,所以我们就需要人为地进行样本的调整,让实验组和控制组实现“完美的控制变量”。
准实验(Quasi-experiment)常见的方法有:Matching匹配、Weighting加权、DID双重差分
Matching匹配
常见的策略是PSM(Propensity Score Matching),本质就是为每个样本找到“双胞胎”,从而实现控制变量。实践中惠对于实验组(对照组)的unit,我们在对照组(实验组)里面找和他相似的unit,然后将两者的差异当做干预对于这个unit的效果,求一个平均就得到干预对于这一群人的平均效果ATE。
Matching缺点就是会浪费一些数据,同事对于高维的情况,我们会难以判断两个样本是否相似。
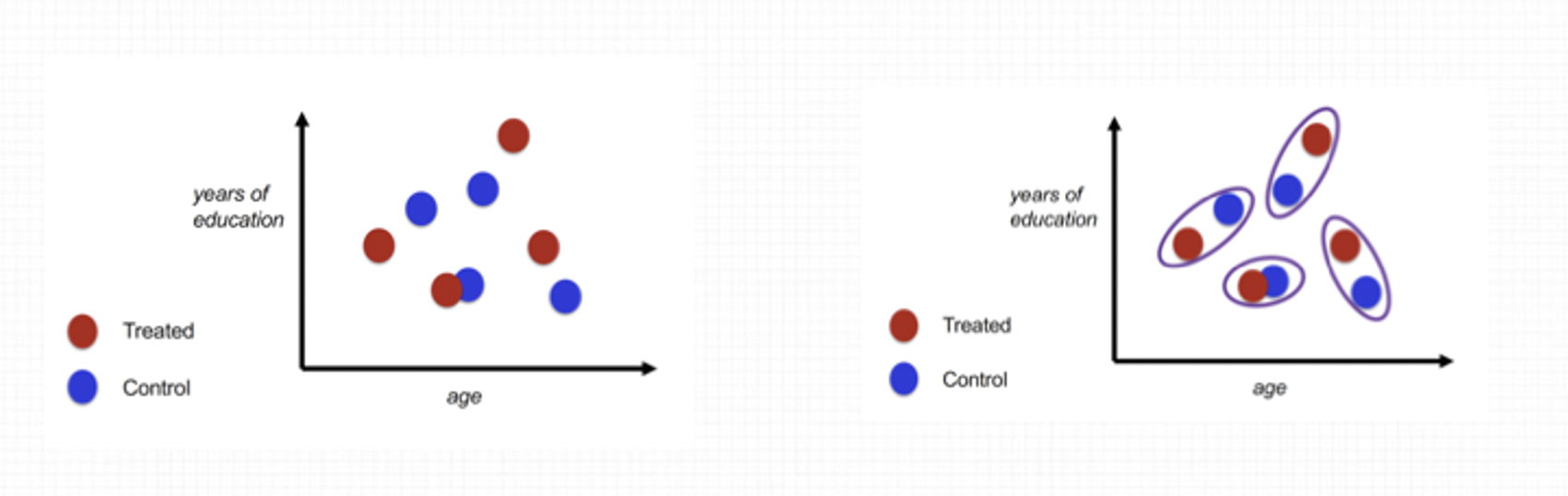
Weighting加权
常用的策略是IPW(Inverse Probability Weighting Estimator),本质就是给每个样本一个“倾向性分数”,通过这个分数来给每个样本赋权,从而实现控制变量,让实验组和对照组的差异变小。
理论上可以证明IPW估计出来的差异是ATE(Average Treatment Effect,即我们想要知道的treatment的效果)的无偏估计,但是当具有某种特性的x的units在实验组或者对照组出现的比例很小的时候,会导致我们估计出来的倾向性得分趋进于0或者1,然而倾向性得分是在units的权重函数的分母上面的,使得IPW虽然无偏(bias=0)但是波动很大(variance很大)。
为了解决这个问题,人们通常会利用估计出来的倾向性得分的分位数将所有样本分层(stratification),然后将每一层里面的样本当做同质的,计算一下每一层里面实验组和对照组之间的差异,然后以每一层的样本量为权重,每一层差异的加权平均,当做所有样本的干预效果�(bias增加,variance下降)。
IPW的准确性直接取决于倾向性分数的构建。

DID双重差分
本质就是找到一个有“平行趋势”的样本,然后对比两个样本之间的差异来确定Treatment Effect。
反事实
这种情况下,不存在控制组,我们只能通过机器学习模型来产生反事实的样本结果。
常见的方法有:增益模型(Uplift model)、因果森林、马尔可夫链、夏普里值
Uplift
用于估算ITE(Individual Treatment Effect)。以广告投放为例,uplift model的核心逻辑就是先用小样本做一个实验组(投广告)和对照组(不投广告),然后分别用实验组和对照组的数据建模,预测他们人们购买的概率,实验组为模型A(预测看完广告购买的概率),对照组为模型B(预测没看广告购买的概率)。接下来对每一个人都跑一遍模型A和模型B,两者的概率差即为uplift value。
基于uplift value和两个模型的预测结果,我们可以很容易把人分为以下四个象限,就能够知道什么人应该投广告,什么人不需要投广告。

常见建模思路